| KAZUSOFT
NetNewsログのXML化 FAQ集を作る XMLの変換(HTML化) KELFをXMLエディタ風に KazusoftのHPを素材に (番外)このハウツーの作成 |
| W3C仕様関係各種の情報XSLTプロセッサ |
この例では、ダウンロードしたネットニュースの記事を、記事同士の関連性を生かした上で、インターネット・エクスプローラ(以下IEと略します。)などのブラウザなどで表示できる形に加工する方法を示します。
ネットニュース記事は、WinVnJなどを使ってダウンロードし、テキスト形式のファイルになっているものとします。
例として次のファイルを使います。
上のfakenews.txtはこのハウツーのために作った偽記事です(^^ゞ。
本当のネットニュース記事を使えれば簡単でいいのですが、そうすると記事作者のみなさまの著作権を冒すことになりますので、筆者が勝手に作り上げた架空の記事集を素材にさせていただきます。
手元に使えるニュースログがありましたら、どうぞそれを使ってください。
KELFのインポート機能でメーラーから取り込んだメール類に対しても、ここで示すのとまったく同じ要領でXML化できます。
2. ファイルを読み込む
ネットニュース記事は、WinVnJなどを使ってダウンロードし、テキスト形式のファイルになっているものとします。
例として次のファイルを使います。
上のfakenews.txtはこのハウツーのために作った偽記事です(^^ゞ。
本当のネットニュース記事を使えれば簡単でいいのですが、そうすると記事作者のみなさまの著作権を冒すことになりますので、筆者が勝手に作り上げた架空の記事集を素材にさせていただきます。
手元に使えるニュースログがありましたら、どうぞそれを使ってください。
KELFのインポート機能でメーラーから取り込んだメール類に対しても、ここで示すのとまったく同じ要領でXML化できます。
素材ファイル(./xml/text/fakenews.txt)をKELFに読み込まなければなにごとも始まりません。
98番のNetNewsログ用文法を使います。文法番号が違っているならメインメニューの「ファイル」⇒「文法変更」で98番に変更してください。
メールを扱うのなら、インポートコマンドを使い、メーラーから読み込めばOKです。
記事のひとつひとつ、あるいはメールのひとつひとつが、ひとつのセクションに対応しましたか?
3. エクスポートを実行
98番のNetNewsログ用文法を使います。文法番号が違っているならメインメニューの「ファイル」⇒「文法変更」で98番に変更してください。
メールを扱うのなら、インポートコマンドを使い、メーラーから読み込めばOKです。
記事のひとつひとつ、あるいはメールのひとつひとつが、ひとつのセクションに対応しましたか?
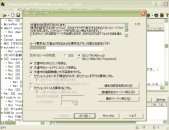 コマンドは、メインメニューの「ファイル」グループ内にあります。
コマンドは、メインメニューの「ファイル」グループ内にあります。実行するとウィザードが起動し、「XMLへのエクスポート」という最初のページが開きます。(左の画像をクリックすると拡大画像を表示します。)
スタイルシートとして
CSS
XSL(TR/WD-xsl)
XSL(1999/XSL/Transform)
の3種類が表示されており、デフォルトはXSL(TR/WD-xsl)になっていると思います。
スタイルシートというのは、XMLを、IEなどのブラウザで表示する方法を書いたものです。そして、CSSやXSLというのは、その書き方を規定したものです。
CSSはカスケーディングスタイルシートと呼ぶ方法で書きます。
XSLはeXtensible Stylesheet Languageという言語を使い書きます。
XSLの背後にある括弧内の文字はネームスペースと呼ばれるものの一部です。完全な形で書くと、それぞれ
http://www.w3.org/TR/WD-xsl
http://www.w3.org/1999/XSL/Transform
になります。
かなり飛躍して言えば、ここではこれは仕様のバージョンだと考えてください。同じXSLでも仕様に差異があります。それぞれで書き方が変わってきます。(このステップではKELFがすべて自動的に書きます。)
5. 形式を選ぶ
CSS
XSL(TR/WD-xsl)
XSL(1999/XSL/Transform)
の3種類が表示されており、デフォルトはXSL(TR/WD-xsl)になっていると思います。
スタイルシートというのは、XMLを、IEなどのブラウザで表示する方法を書いたものです。そして、CSSやXSLというのは、その書き方を規定したものです。
CSSはカスケーディングスタイルシートと呼ぶ方法で書きます。
XSLはeXtensible Stylesheet Languageという言語を使い書きます。
XSLの背後にある括弧内の文字はネームスペースと呼ばれるものの一部です。完全な形で書くと、それぞれ
http://www.w3.org/TR/WD-xsl
http://www.w3.org/1999/XSL/Transform
になります。
かなり飛躍して言えば、ここではこれは仕様のバージョンだと考えてください。同じXSLでも仕様に差異があります。それぞれで書き方が変わってきます。(このステップではKELFがすべて自動的に書きます。)
この例ではCSSを選択してみましょう。
というのは、代表的なブラウザのひとつであるネットスケープナビゲーター(以下NNと略します。)は、この文章を執筆している時点での最新バージョンver6.1では、まだXSLに対応していません。
また、IEも、より柔軟な仕様である、http://www.w3.org/1999/XSL/Transformをサポートしたのはver5.01からで、ver5.00はhttp://www.w3.org/TR/WD-xslしかサポートしていません。
対応ということで言えば、ブラウザでXMLそのものを直接表示できるのは、IEならver5.0以降、NSならver6.0以降に限定されます。
・・・と、こんな風に書くと、
でも、心配いりません。
文書をXML化し、それをさらにhtml化すれば、どんなブラウザでも表示できるようになります。この方法は後で書きます。大きな商用ウェブサイトは、多かれ少なかれ、データペース化した文書を種々の方法でhtml化することにより、運用されています。
XMLはデータ貯蔵用の仕様として優れたものです。
だから作成するXMLをデータ貯蔵用と割り切ることも可能です。
表示を考えないなら、スタイルシートは関係ありません。ただ、KELF内部では、スタイルシートの方式によって、出力するXMLのタグ様式を少し変えています。データ貯蔵用の場合は、XSL(1999/XSL/Transform)を選択してください。もっとも柔軟性があります。
6. 入れ子構造
というのは、代表的なブラウザのひとつであるネットスケープナビゲーター(以下NNと略します。)は、この文章を執筆している時点での最新バージョンver6.1では、まだXSLに対応していません。
また、IEも、より柔軟な仕様である、http://www.w3.org/1999/XSL/Transformをサポートしたのはver5.01からで、ver5.00はhttp://www.w3.org/TR/WD-xslしかサポートしていません。
対応ということで言えば、ブラウザでXMLそのものを直接表示できるのは、IEならver5.0以降、NSならver6.0以降に限定されます。
・・・と、こんな風に書くと、
「なんだ。
XMLで文書を作っても、対応しているのはごく限られたブラウザだけじゃないか」
と思われるかもしれません。XMLで文書を作っても、対応しているのはごく限られたブラウザだけじゃないか」
でも、心配いりません。
文書をXML化し、それをさらにhtml化すれば、どんなブラウザでも表示できるようになります。この方法は後で書きます。大きな商用ウェブサイトは、多かれ少なかれ、データペース化した文書を種々の方法でhtml化することにより、運用されています。
XMLはデータ貯蔵用の仕様として優れたものです。
だから作成するXMLをデータ貯蔵用と割り切ることも可能です。
表示を考えないなら、スタイルシートは関係ありません。ただ、KELF内部では、スタイルシートの方式によって、出力するXMLのタグ様式を少し変えています。データ貯蔵用の場合は、XSL(1999/XSL/Transform)を選択してください。もっとも柔軟性があります。
もう一箇所、設定を変更しましょう。
やはり最初のページに、
「セクションによる入れ子構造を作らず、各セクションを並行要素にする」
というチェックボックスがあり、デフォルトはオフになっているはずです。
これをオンにします。
オフでも問題ありませんが、作成するXML文書をデータ貯蔵用と見た場合、この文書に関しては入れ子構造を作らないほうがよいと思います。
少し詳しく説明します。
KELFはネットニュース記事を解析し、各記事の親子関係から次のような構造を作っています。(模式的に書きます。)
親記事1
子記事1
子記事2
子記事3
孫記事1
孫記事2
子記事4
親記事2
子記事1
孫記事1
親記事3
もし上のチェックボックスをオフのまま、入れ子構造を作ったとすると、できあがるXMLの構造は、上の構造をそのままに、
<rank0>親記事1
<rank1>子記事1</rank1>
<rank1>子記事2</rank1>
<rank1>子記事3
<rank2>孫記事1</rank2>
<rank2>孫記事2</rank2>
</rank1>
<rank1>子記事4</rank1>
</rank0>
<rank0>親記事2
<rank1>子記事1
<rank2>孫記事1</rank2>
</rank1>
</rank0>
<rank0>親記事3</rank0>
というようになります。
<xxx>から</xxx>までがXMLのひとつの要素です。前者を開始タグ、後者を終了タグといいます。中身がないときは両方をくっつけて<xxx/>と書くことができます。
各記事の関係を重視したいときは、こうした構造をとるのもいいです。
しかし、通常、記事はそれぞれ独立したものです。ひとつの記事要素のなかに、他の記事要素が含まれる構造には少し抵抗を感じます。
そこで入れ子構造は作らず、記事の親子関係はリンク関係だけで構築することにします。入れ子構造を作らないなら各記事は同等です。だからすべて同じ要素名を使いましょう。(デフォルトはセクションランクによって要素名を変えます。)
というわけで、
「全セクションで同じ要素名を使う」
もチェックします。
できあがるXML文書の構造は、
<rank0>親記事1</rank0>
<rank0>子記事1</rank0>
<rank0>子記事2</rank0>
<rank0>子記事3</rank0>
<rank0>孫記事1</rank0>
<rank0>孫記事2</rank0>
<rank0>子記事4</rank0>
<rank0>親記事2</rank0>
<rank0>子記事1</rank0>
<rank0>孫記事1</rank0>
<rank0>親記事3</rank0>
・
・
・
という平板なものになり、各記事の関係は、要素のidを使ったリンク関係のみで表現されます。
7. 最終ページへ飛ぶ
やはり最初のページに、
「セクションによる入れ子構造を作らず、各セクションを並行要素にする」
というチェックボックスがあり、デフォルトはオフになっているはずです。
これをオンにします。
オフでも問題ありませんが、作成するXML文書をデータ貯蔵用と見た場合、この文書に関しては入れ子構造を作らないほうがよいと思います。
少し詳しく説明します。
KELFはネットニュース記事を解析し、各記事の親子関係から次のような構造を作っています。(模式的に書きます。)
親記事1
子記事1
子記事2
子記事3
孫記事1
孫記事2
子記事4
親記事2
子記事1
孫記事1
親記事3
もし上のチェックボックスをオフのまま、入れ子構造を作ったとすると、できあがるXMLの構造は、上の構造をそのままに、
<rank0>親記事1
<rank1>子記事1</rank1>
<rank1>子記事2</rank1>
<rank1>子記事3
<rank2>孫記事1</rank2>
<rank2>孫記事2</rank2>
</rank1>
<rank1>子記事4</rank1>
</rank0>
<rank0>親記事2
<rank1>子記事1
<rank2>孫記事1</rank2>
</rank1>
</rank0>
<rank0>親記事3</rank0>
というようになります。
<xxx>から</xxx>までがXMLのひとつの要素です。前者を開始タグ、後者を終了タグといいます。中身がないときは両方をくっつけて<xxx/>と書くことができます。
各記事の関係を重視したいときは、こうした構造をとるのもいいです。
しかし、通常、記事はそれぞれ独立したものです。ひとつの記事要素のなかに、他の記事要素が含まれる構造には少し抵抗を感じます。
そこで入れ子構造は作らず、記事の親子関係はリンク関係だけで構築することにします。入れ子構造を作らないなら各記事は同等です。だからすべて同じ要素名を使いましょう。(デフォルトはセクションランクによって要素名を変えます。)
というわけで、
「全セクションで同じ要素名を使う」
もチェックします。
できあがるXML文書の構造は、
<rank0>親記事1</rank0>
<rank0>子記事1</rank0>
<rank0>子記事2</rank0>
<rank0>子記事3</rank0>
<rank0>孫記事1</rank0>
<rank0>孫記事2</rank0>
<rank0>子記事4</rank0>
<rank0>親記事2</rank0>
<rank0>子記事1</rank0>
<rank0>孫記事1</rank0>
<rank0>親記事3</rank0>
・
・
・
という平板なものになり、各記事の関係は、要素のidを使ったリンク関係のみで表現されます。
あとはすべてデフォルトのままXMLを作成してみましょう。
「最終ページへ飛ぶ」ボタンをクリックします。
「XML出力」という最終ページがあらわれます。
「XML出力後、ブラウザを起動する」チェックボックスがチェックされていることを確認し、「完了」ボタンをクリックします。
fakenews.xmlとfakenews.cssという二つのファイルが生成されるはずです。これらはテキストファイルですので、KELFやSARIで内容を見ることができます。
ブラウザの起動に数秒かかるかもしれません。
どうですか。無事、XML化した文書が表示されましたか?
マシンの標準ブラウザがIE 5.0以降、NS 6.0以降なら、下の画像のような感じで表示されるはずです。(画像をクリックすると拡大画像を表示します。)
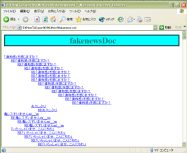
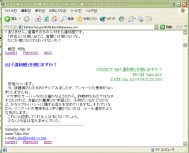
冒頭部にはタイトルと目次が表示されます。
各記事には、タイトルとともに、記事の著者や日付などが付記されてます。
また各記事の下部には、前の記事や次の記事へのリンクとともに、親記事があるときは親記事へのリンクが、表示されます。
これらの表示細目や、表示の体裁はかなり自由にカスタマイズが可能です。
前述したように、ブラウザがXMLに対応していないなら、うまく表示されません。
その場合はXMLを表示するためにはhtmlに変換する必要があります。
この変換の意味と具体的な方法は別項で説明します。
表示できなかった場合、下のfakenews.htmlをクリックすれば、参考としてhtmlに変換したものを表示します。
「最終ページへ飛ぶ」ボタンをクリックします。
「XML出力」という最終ページがあらわれます。
「XML出力後、ブラウザを起動する」チェックボックスがチェックされていることを確認し、「完了」ボタンをクリックします。
fakenews.xmlとfakenews.cssという二つのファイルが生成されるはずです。これらはテキストファイルですので、KELFやSARIで内容を見ることができます。
ブラウザの起動に数秒かかるかもしれません。
どうですか。無事、XML化した文書が表示されましたか?
マシンの標準ブラウザがIE 5.0以降、NS 6.0以降なら、下の画像のような感じで表示されるはずです。(画像をクリックすると拡大画像を表示します。)
冒頭部にはタイトルと目次が表示されます。
各記事には、タイトルとともに、記事の著者や日付などが付記されてます。
また各記事の下部には、前の記事や次の記事へのリンクとともに、親記事があるときは親記事へのリンクが、表示されます。
これらの表示細目や、表示の体裁はかなり自由にカスタマイズが可能です。
前述したように、ブラウザがXMLに対応していないなら、うまく表示されません。
その場合はXMLを表示するためにはhtmlに変換する必要があります。
この変換の意味と具体的な方法は別項で説明します。
表示できなかった場合、下のfakenews.htmlをクリックすれば、参考としてhtmlに変換したものを表示します。